I worked on a video-based vehicle counting system (VCS) for my final year (BSc) project. I shared a demo on Twitter that went semi-viral!
In this article, I’ll explain why and take you through how I built it, discussing how it works, how I learned the libraries used, the components of the system, the algorithms and models I experimented with and the results obtained. Let’s get started!
TL;DR: I built a video-based vehicle counting system using Python/OpenCV. You can find the code on my GitHub.

How it works
The vehicle counting system I built is made up of three main components: a detector, tracker and counter. The detector identifies vehicles in a given frame of video and returns a list of bounding boxes around the vehicles to the tracker. The tracker uses the bounding boxes to track the vehicles in subsequent frames. The detector is also used to update the trackers periodically to ensure that they are still tracking the vehicles correctly. The counter counts vehicles when they leave the frame or makes use of a counting line drawn across a road.
Why vehicle counting?
Computer Vision (CV) had been on my list of things to learn for a long time so I decided to use the opportunity of my final project to learn it. I actually wanted to build a turn-based or real-time strategy game that used a healthy dose of AI but I knew I wouldn’t have been able to complete it in time for my defence so I figured a CV project was the way to go as I’d very likely get to use Machine Learning (ML).
Computer Vision is an interdisciplinary field concerned with giving computers the ability to “see” or be able to understand the contents of digital images such as photos and videos. While vision is a trivial task for humans and animals, it’s currently quite difficult for machines. However, a lot of progress has been made in the field in the last few decades and new techniques and technologies to make CV faster and more accurate are actively being researched.
A vehicle counting system, as you might have already inferred, is a system that counts vehicles on the road. Why would you want to build one? Why would you want to count vehicles on the road? Here are some reasons:
- Traffic management and planning: If you have a good sense of the volume of traffic moving along a given road or network of roads, you can better understand congestion and then manage and/or make plans to reduce/eliminate it. Vehicle count data is very useful to urban city planners and transport authorities.
- Traffic control: No one likes to be stuck behind a red light especially when the road is free. Vehicle counting systems can be integrated with traffic light control software to intelligiently direct vehicles based on the current traffic situation in real time.
- Parking management: A VCS can be installed at the entrance of a parking lot to monitor vehicles coming in and going out in order to determine whether there are slots available at any given time. It can also be used to ensure the number of vehicles in a given place (such as a hotel or events center) does not exceed its capacity by controlling Automatic Barrier Gates as opposed to issuing tags.
- Advertising: Billboard advertisers and their clients are interested in the volume of vehicular traffic along a road where they have ads or where they want to install a billboard because they can make estimates of the number of people who see their ads per time using the data.
Why video?
There are a handful of ways to count vehicles on the road from manual counts to pneumatic tubes to piezoelectric sensors. Why was video used? Why is it preferred?
- Sensor data (video footage) can be used to verify the system’s results which makes it easier and faster to evaluate and improve the system.
- The footage can also be used for other purposes including surveillance, automatic plate number recognition, vehicle type detection and vehicle speed detection to name a few.
- It is relatively cheaper to implement and scale as a permanent vehicle counting system compared to other systems.
- It can track and count multiple vehicles moving in different directions across several lanes.
Learning OpenCV
Since I’m proficient in Python, OpenCV was the logical tool to use. OpenCV is an open-source library made up of a collection of modules for performing real-time Computer Vision tasks. I used the YouTube tutorial series OpenCV with Python for Image and Video Analysis by Harrison Kinsley of PythonProgramming.net to learn the basics. I was quickly able to learn how to load images and videos, overlay text, shapes or images on media, manipulate pixels on images as a pre-processing step or to produce a visual, perform background substraction to detect objects, run Haar Cascades for object detection etc.
Components of the VCS
I had little or no idea on how to build a VCS so I looked online for inspiration. I found a C++ project which used background subtraction and decided to port it to Python. This gave me to opportunity to go through every line of the code and understand it at a deeper level. I completed the port and tested it out on the traffic scenes I’d recorded. The results were very poor. I began thinking of better algorithms and techniques to use. I broke the problem down into three sub-problems: detection, tracking and counting.
Detection
This is a crucial and probably the most important part of building a VCS. Detection is an aspect of CV and image processing concerned with identifying instances of objects of a certain class, like vehicles or people, in images and videos. Popular areas of interest in object detection include pedestrian detection and face detection. Object detection can be applied in solving hard problems in areas like image search and video surveillance. It is used widely in computer vision tasks including face detection, face recognition, and object tracking.
All object types have special attributes that help in classifying them. For instance, all faces are round. Object detection algorithms use these special attributes to identify objects in images and videos. I experimented with several object detection techniques, most notably background subtraction, Haar Cascades and YOLO.
Background subtraction
The first detector I used to id vehicles was a background substractor. Background or image subtraction is the process of extracting the foreground of an image from its background. If you have a background image like a road without vehicles in it, you can subtract this image from another image of the same road (from the exact same view) which contains vehicles to detect those vehicles. The background pixels would cancel each other out and the objects in the foreground would pop out.
What if you don’t have a background image? You can achieve the same results if the objects you’re interested in detecting are in motion, the background is static and the camera is stationary. In this case, all you have to do is evaluate the difference between consecutive images i.e image 2 minus image 1, image 3 minus image 2, image 4 minus image 3 etc. This works because the pixels of moving objects constantly shift hence are not cancelled out like the background pixels and thus pop out as the foreground.
The images below show what background substraction looks like.

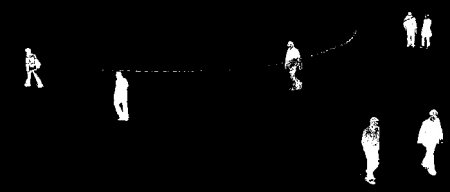
Source: OpenCV Docs
While background substraction was easy to implement and super fast, I was unable to arrive at a suitable threshold for detecting vehicle blobs. Vehicles are not the only objects that move on/across the road. There are pedestrians, animals, people with carts or wheelbarrows, skateboarders etc. Also, objects change in size and shape as they move across the view due to perspective, and vehicles may be occluded by other vehicles in the scene and thus interpreted as one object.
I observed a lot of noise as well mainly due to the waving of trees and commercial activities going on in the background. While noise reduction techniques such as Gaussian Blur and selecting a Region of Interest (ROI) for detection helped, the overall performance of the detector was still underwhelming. After spending quite a while trying to tweak things in order to increase accuracy, I decided I needed another detector.
Haar Cascades
Haar Cascades are object detection models based on the concept of Haar-like features developed by Paul Viola and Michael Jones and published in their 2001 paper titled Rapid Object Detection using a Boosted Cascade of Simple Features. I tried out a car detector Haar Cascade I found online. It produced a lot of false positives which made counts erroneous. I considered creating my own model but it seemed like a Herculean task at the time. I decided to try deep learning instead.
I plan to create a custom Haar Cascade with data got from testing the VCS in the real world in the near future. Haar Cascades are generally a lot faster than deep learning object detection models so if I can get the model to be just as accurate or more accurate than the deep learning alternatives, it might be possible to run the VCS efficiently on devices like Raspberry Pis instead of depending on the cloud for processing power.
If you want to learn more about Haar Cascades, check out this video which explains how the technique works for face detection.
YOLO
YOLO (You Only Look Once) is a popular deep learning model/architecture for object detection. I found out about it through a TED talk given by one of its creators Joseph Redmon and wondered if I could use it in the VCS project. Fortunately, OpenCV provides a deep neural network module with which can be used to import and run YOLO models easily. I downloaded a model trained on the COCO dataset from the YOLO website and tried it out. The results were very good so I stuck with YOLO for detection. I’ve since added support for other deep learning models/libraries. It’s actually quite easy to modify the code to support a model of your choice.
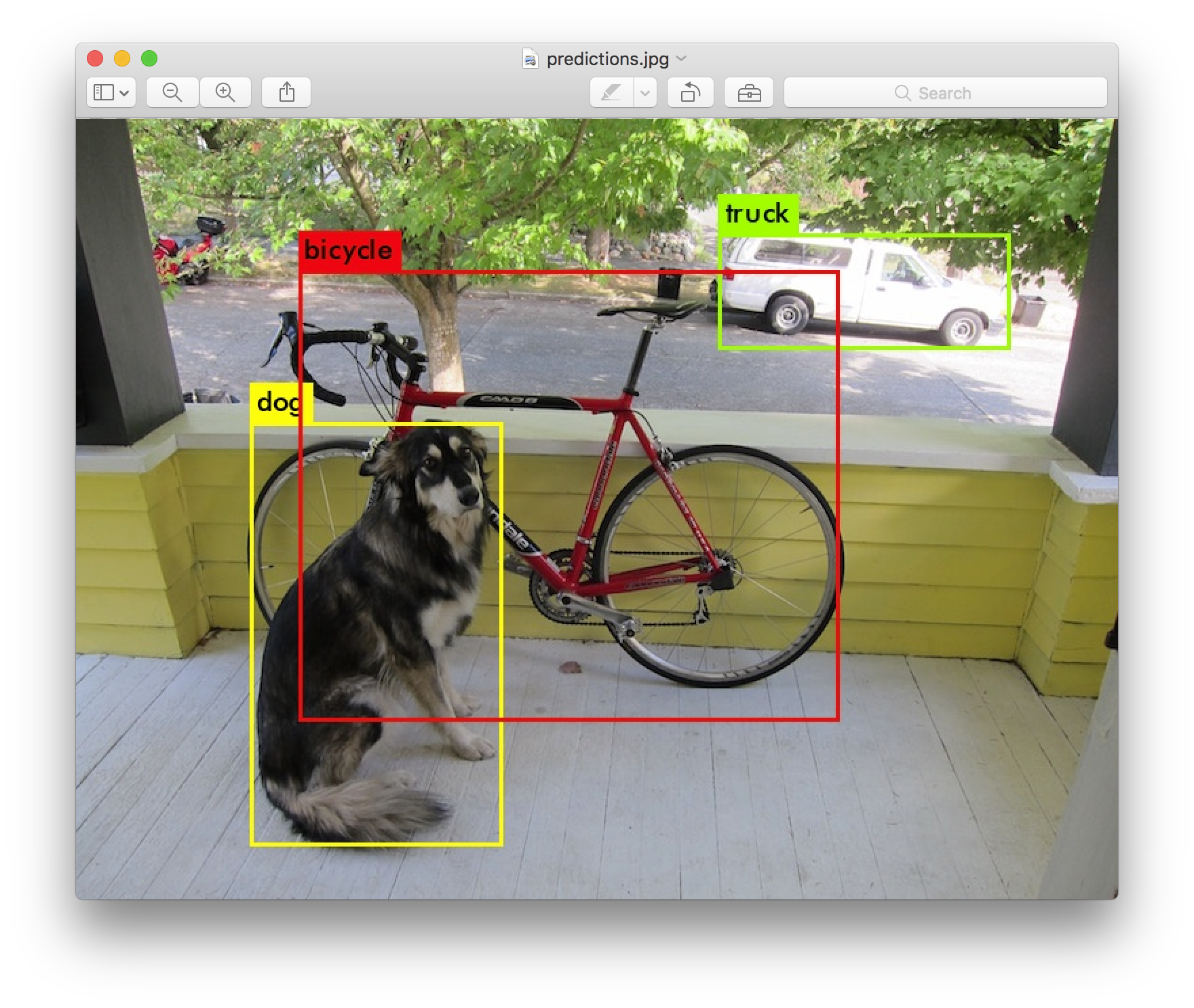
Source: pjreddie.com
If you want to learn more about YOLO, you should definitely take a look at these papers: You Only Look Once: Unified, Real-Time Object Detection and YOLOv3: An Incremental Improvement.
Tracking
Tracking is the process of following the path or movements of an object with the purpose of finding it or observing its course. The uses of video tracking include augmented reality, surveillance and security, video compression and communication, video editing, human-computer interaction, traffic control and medical imaging.
The goal of tracking is to associate target objects in sequential frames of a video. This association can be very hard to accomplish when the objects are moving fast in relation to the frame rate of the video. Things get even more complicated when tracked objects change their orientation over time. In this scenario, video tracking systems normally use a motion model which details how the image of the target might look for several possible orientations of the object.
Centroid tracking
I first experimented with the centroid tracking algorithm since it was easy for me to implement. Centroid tracking works by associating the centroid of a bounding box around a detected object in one frame with a centroid in a subsequent frame based on some measure of proximity between them such as euclidean distance. Aside having to run detection on every frame which is computationally expensive, it was difficult for me to find a good threshold that reliably determines if two consecutive centroids belong to a single object or not. Among other things, the value for this threshold must consider the size of the object, and the frame rate and resolution of the video. After several failed attempts to tweak the algorithm to work well with my test videos, I started looking for alternatives.
OpenCV tracking algorithms (CSRT and KCF)
In my search for better tracking algorithms, I found out that OpenCV has implementations of some state-of-the-art algorithms including BOOSTING, MIL, KCF, TLD, MEDIANFLOW, GOTURN, MOSSE and CSRT. I settled for CSRT (Discriminative Correlation Filter with Channel and Spatial Reliability) and KCF (Kernelized Correlation Filters) because they gave the best results. CSRT, while more accurate, is computationally expensive. In traffic scenes where there are not a lot of vehicles on the road, KCF usually does better.
There was a challenge with CSRT AND KCF however. Vehicles, and thus their bounding boxes, change in size as they move across the frame of a video due to perspective but these trackers can’t adjust the size of their bounding boxes as they track an object. Eventually when an object is large or small enough, the algorithm becomes unable to find the object even though it’s still in frame. To solve this problem, the detector is periodically run to update the trackers with new bounding boxes. But before going for this approach, I experimented with Camshift.
Camshift
CAMshift (Continuously Adaptive Meanshift) is a tracking algorithm developed by Gary Bradski and described in his 1988 paper titled Computer Vision Face Tracking for Use in a Perceptual User Interface. Unlike CSRT and KCF, it adapts a bounding box with the size and rotation of its target object. However, I observed a problem which made it unusable for the VCS. Camshift was having a hard time tracking vehicles because they were moving too fast for it. It performed pretty well when I tried to track slow-moving objects but was always left behind by fast-moving ones (e.g vehicles) shortly after the tracking began.
Counting
Counting was the easiest part! Vehicles are counted when they leave the frame or cross a line at an exit point of the frame. Using a counting line makes it easier to count vehicles moving in a certain direction.
Contribute
The VCS is free and open source software available on GitHub. You can contribute to the project by taking it for a spin and reporting issues/bugs or working on parts of it that need improvement.
Last modified on 2023-03-21